
MS, 멀티모달 대규모 언어 모델 ‘코스모스-1’ 공개
텍스트를 이해하고 이미지를 인식해 다양한 텍스트를 생성
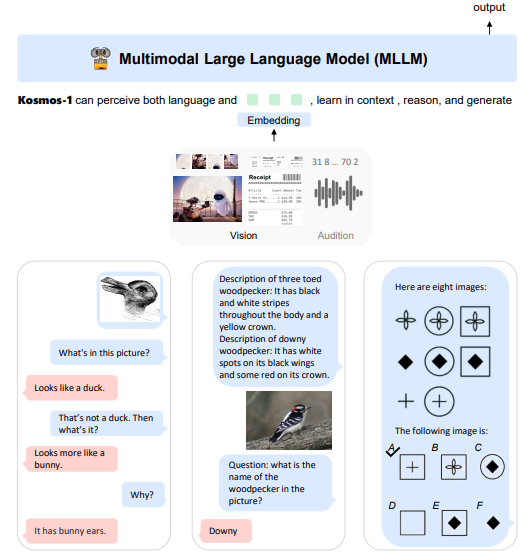
마이크로소프트(MS)가 시각 및 언어 기능을 갖춘 멀티모달 대형 언어 모델(MLLM) ‘코스모스-1(Kosmos-1)’을 공개했다.
이로서 MS가 그동안 오픈AI에 거액을 투자한 뒤 '챗GPT'를 검색과 오피스 및 윈도 프로그램에 탑재하는 등 적극 활용하는 동시에 내부에서도 인공지능(AI)을 자체 개발하는 투트랙 전략을 구사해 왔다는 사실이 밝혀졌다.
아스테크니카는 2일(현지시간) MS가 공개한 '코스모스-1'은 이미지를 분석하고 그에 대한 질문에 답하고, 이미지에서 텍스트를 읽고, 이미지에 대한 캡션을 작성하고, 지능 테스트를 수행할 수 있는 멀티모달 모델이라고 소개했다.
멀티모달은 여러 가지 유형의 지각과 입력 양식을 인식하고 이해하는 능력이다.
특히 텍스트, 오디오, 이미지 및 비디오와 같은 다양한 입력 모드를 통합하는 멀티모달 AI는 인간 수준에서 일반 작업을 수행할 수 있는 범용인공지능(AGI)을 구축하는 데 핵심 단계로 꼽힌다.
AGI는 AI 분야에서 MS의 파트너인 오픈AI나 구글의 자회사인 딥마인드의 명시적인 목표이기도 하다.
MS는 코스모스-1을 오픈AI의 개입 없이 독자 구축한 모델이라고 밝혔다. 챗GPT와 같은 텍스트 전용 대규모 언어 모델(LLM)과 같은 자연어 처리에 뿌리를 두고 있기 때문에 ‘MLLM(multimodal large language model)’이라고 부른다는 설명도 곁들였다.
코스모스-1이 텍스트가 아닌 이미지 입력을 받아들이려면 먼저 이미지를 LLM이 텍스트 처럼 이해할 수 있도록 일련의 토큰으로 변환해야 한다.
이미지를 표현한 토큰 시퀀스는 이미지 시퀀스의 시작과 끝을 표시하는 특수 토큰 <image>와 </image>로 구분한다. 예를 들어 ‘<s>텍스트</s>’는 텍스트 입력이고 ‘<s>텍스트 토큰 시퀀스<image>이미지 토큰 시퀀스</image>텍스트 토큰 시퀀스</s>’은 이미지-텍스트 입력이다.
임베딩 모듈은 텍스트와 기타 입력 양식을 모두 벡터로 인코딩하는 데 사용된다. 각 입력 토큰은 조회 테이블을 사용해 숫자로 표현되는 임베딩 벡터에 매핑된다. 그런 다음 임베딩이 디코더에 공급된다.
대규모 언어 모델인 코스모스-1은 이미지나 오디오와 같은 다른 유형의 입력 양식을 외국어처럼 간주하고 처리한다. 즉 코스모스-1은 모든 유형의 입력 양식을 텍스트 처럼 이해하고, 설명하고, 평가하고, 처리할 수 있다.
코스모스-1의 학습 데이터는 텍스트 말뭉치, 단어-이미지 쌍 및 이미지와 텍스트를 결합한 다양한 멀티모달 데이터 컬렉션으로 구성했다. 이미지 구성 요소에는 ‘레이온(LAION)’ 데이터셋을 사용했고, 텍스트 구성 요소에서는 ‘파일(The Pile)’이라는 800GB의 영어 텍스트 리소스와 인터넷의 ‘컴몬 크롤(Common Crawl)’ 데이터 세트를 사용했다.
MS는 학습 후 언어 이해, 언어 생성, 광학 문자 인식 없는 텍스트 분류, 이미지 캡션, 시각적 질문 응답, 웹 페이지 질문 응답, 제로샷 이미지 분류를 포함한 여러 테스트에서 코스모스-1은 다른 최신 모델을 능가했다고 밝혔다.

코스모스-1은 입가에 미소를 지으며 종이를 들고 있는 새끼 고양이의 이미지에 대해 '이 사진이 왜 재미있는지 설명하시겠습니까?’라는 프롬프트를 제시했을때 ‘고양이는 고양이에게 미소를 주는 마스크를 쓰고 있다’라고 대답했다.
또 10시 10분을 가리키는 시계 이미지에서 정확히 시간을 읽어 내고, 4 + 5의 이미지로부터 합계를 계산하고, ‘토치스케일(TorchScale)이 무엇입니까?’라고 물었을 때 깃허브 페이지를 기반으로 설명을 하고, 애플 워치에서 심박수를 읽을 수 있었다.
이밖에 윈도우 10 사용자에게 컴퓨터를 다시 시작하는 방법을 알려주는 것부터 검색한 웹 페이지를 읽는 것, 기기에서 건강 데이터를 해석하는 것, 이미지 캡션을 다는 것까지 여러 상황에서 작업을 자동화할 수 있는 가능성을 보여준다.

흥미로운 것은 일련의 그림 모양을 제시하고 순서를 완성하도록 하는 방식으로 시각적 지능(IQ)를 측정하는 레이븐 지능 테스트 결과다. 코스모스-1은 레이븐 테스트의 질문에 22%만 올바르게 답했다. 하지만 LLM이 시각 인식을 언어 모델과 결합해 비언어적 추론을 수행할 수 있는 가능성을 보여줬다는 점에서는 나름 의미가 있는 것으로 평가된다.
박찬 위원 cpark@aitimes.com
원문 : https://www.aitimes.com/news/articleView.html?idxno=149758

'[IT 알아보기] > IT 소식' 카테고리의 다른 글
| [IT 소식] 구글 "1천개 언어 이해·생성하는 모델 만든다" (0) | 2023.03.07 |
|---|---|
| [IT 소식] 챗GPT가 쓴 과학자의 '나 사용법' (0) | 2023.03.07 |
| [IT 소식] 메타버스 기업 더샌드박스, 독일 게임사 스바이퍼 인수 (0) | 2023.03.04 |
| [IT 소식] 인공지능이 로봇도 제어한다...MS, '챗GPT'로 로봇 제어 연구 (0) | 2023.03.03 |
| [IT 소식] SK텔레콤 '에이닷', 친구와 소통하듯 진화 (0) | 2023.03.03 |